فيما سبق كان اهتمامنا بقيمة المتغير 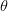 (أو المَعْلَمة كما تسمى في بعض المصادر) لاستعمالها من أجل الاستدلال الاحصائي لكن في بعض الأحيان يكون لدينا فرضية حول قيمة المتغير ونريد أن نعرف مامدى صحة هذه الفرضية. مثلا, نريد التأكد من صحة الفرضية القائلة أن معدل طول الرجال أكبر من معدل طول النساء, أو مثلا التأكد من أن تعبير جين معين في الخلايا السرطانية أكبر من نسبة تعبيره في الخلايا العادية. في هذه الحالة يمكننا القيام باختبار احصائي يسمى إختبار الفرضيات.
(أو المَعْلَمة كما تسمى في بعض المصادر) لاستعمالها من أجل الاستدلال الاحصائي لكن في بعض الأحيان يكون لدينا فرضية حول قيمة المتغير ونريد أن نعرف مامدى صحة هذه الفرضية. مثلا, نريد التأكد من صحة الفرضية القائلة أن معدل طول الرجال أكبر من معدل طول النساء, أو مثلا التأكد من أن تعبير جين معين في الخلايا السرطانية أكبر من نسبة تعبيره في الخلايا العادية. في هذه الحالة يمكننا القيام باختبار احصائي يسمى إختبار الفرضيات.
رأينا في جزء التقدير النُقطي أن قيمة التقدير لديها نسبة من التباين, فلو فرضت أن المتوسط يساوي 0 ثم قدرته ووجدت أنه 0.5 هذا لا يعني أن قيمة المتغير الحقيقية مختلفة عن الصفر اختلافا جوهريا, لأن القيمة التي تم تقديرها كانت مبنية على العينة المأخوذة وليس كل المجتمع, لهذا يجب حساب قيمة احصائية تخبرك بمدى صحة فرضيتك وهو المبدا وراء إختبار الفرضيات.
رياضيا يمكننا أن نرى أن المسألة تتلخص في تحديد ما إذا كان المتغير ينتمي إلى مجموعة 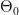 التي نفترضها أو المجموعة
التي نفترضها أو المجموعة 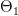 (في عادة النفي) . نسمي الفرضية القائلة بأن
(في عادة النفي) . نسمي الفرضية القائلة بأن 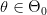 بـ الفرضية الصفرية ( Null Hypothesis) أو فرضية العدم (مثلا لا يوجد علاقة بين الطول والجنس) ونرمز لها بالرمز
بـ الفرضية الصفرية ( Null Hypothesis) أو فرضية العدم (مثلا لا يوجد علاقة بين الطول والجنس) ونرمز لها بالرمز 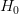 ونسمي الفرضية الأخرى بـ الفرضية البديلة ونرمز لها بـ
ونسمي الفرضية الأخرى بـ الفرضية البديلة ونرمز لها بـ 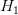 . أو بصفة عامة نكتب:
. أو بصفة عامة نكتب:
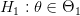 ضد
ضد 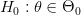
يمكننا تلخيص بعض الحالات في هذا الجدول:
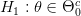 ضد
ضد
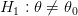 ضد
ضد 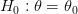
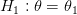 ضد
ضد
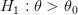 ضد
ضد 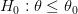
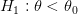 ضد
ضد 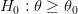
في العادة نريد أن نثبت أن الفرضية الصفرية خاطئة. مثلا أفرض أن تعبير الجين متساوي في الخلية السرطانية و الخلايا السليمة وأحاول حساب قيمة حسابية تخبرني بمدى صدق الفرضية الصفرية, في العادة تسمى هذه القيمة p-value مثلا إذا كانت هذه القيمة تساوي 0.04 هذا يعني أنه لدي إمكانية 96% أن أقول أن تعبير الجين مختلف بين العينتين ونسبة الخطأ في هذا التصريح هي 4%.
لكن لا نستبق الأحداث الآن وسنصل إلى مفهوم الـ p-value فيما بعد.
طرق القيام بإختبار الفرضيات:
الآن بعدما كتبنا المشكلة بطريقة رياضية نريد أن تكون لدينا دالة رياضية تمكننا بالقيام بالاختبار. هناك عدة طرق يمكن استعمالها للقيام بذلك. في هذا المقال سوف نشرح الطريقتين الأكثر استعمالا وهما إختبار نيمان-بيرسن (Neyman-Peatson test) و إختبار تناسب دوال الإمكان ( Likelihood Ratio Test). بناءا على مبدا هذين الطريقتين يمكننا استنتاج معادلات طرق الإختبار المعروفة مثل إختبار تي (T-test) و الكاي تربيع (test-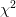 ), ... إلخ.
), ... إلخ.
1) إختبار نيمان-بيرسن ( Neyman-Pearson Test):
يستعمل هذا النوع من الاختبار عند المقارنة بين قيمتين. مثلا لدينا اختبار وندري أن قيمة المتغير تكون إما 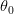 أو
أو 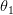 . أو إختصارا:
. أو إختصارا:
ضد
إذا كانت دالة الإمكان للعينة هي 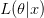 يمكن حساب منطقة رفض الفرضية الصفرية بالمجال الذي تكون فيه قيم دالة الإمكان أكبر عندما نعوض بقيمة المتغير و نعرف منطقة القبول بالمجال التدي تكون فيه دالة الامكان أكبر عندما نعوض بقيمة .
يمكن حساب منطقة رفض الفرضية الصفرية بالمجال الذي تكون فيه قيم دالة الإمكان أكبر عندما نعوض بقيمة المتغير و نعرف منطقة القبول بالمجال التدي تكون فيه دالة الامكان أكبر عندما نعوض بقيمة .
رياضيا يمكننا تعريف منطقة الرفض 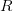 بـ:
بـ:
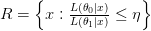
ومنطقة القبول بـ:
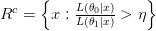
إذا كانت الفرضية البديلة صحيحة فإنه في حالة استعمال سيكون إحتمال أن تكون البيانات في منطقة الرفض صغيرا إذْ أننا نتوقع أن تكون كل القيم قادمة من الدالة ذات المتغير . لهذا من أجل تحدد قيمة 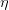 بالقيمة التي تسمح لنا بقبول بنسبة خطأ
بالقيمة التي تسمح لنا بقبول بنسبة خطأ 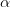 . أو بطريقة أسهل يمكننا كتابة:
. أو بطريقة أسهل يمكننا كتابة:
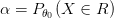
في العادة نتقبل الفرضية البديلة بنسبة خطأ 1%, 5% أو حتى 10% في بعض التطبيقات الطبية.
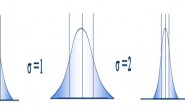
رسم توضيحي بين منطقة القبول
1) إختبار تناسب دوال الامكان (Likelihood Ration Test) :
يعتبر هذا الاختبار تعميما لاختبار نيمان-بيرسن, حيث أنه في هذه الحالة عوض المقارنة بين قيمتين للمتغير, يتم إختبار ما إذا كان المتغير ينتمى إلى مجال من القيم أو آخر. اختصارا يمكن كتابة:
ضد
في هذه الحالة يمكننا التفكير كالتالي: بما أن دالة الإمكان هي التي تخبرنا بمدى تفسير النموذج الاحصائي للبيانات, فيكفي أن أقارن أكبر قيمة للدالة في المجال وأكبر قيمة للدالة في المجال وبالتالي يصبح لدي إختبار مشابه لاختبار نيمان-بيرسن ونقوم بتحديد قيمة الخطأ ... إلخ.
يمكننا تعريف القيمة الاحصائية للاختبار (Test statistics) كالتالي:
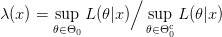
وبعدها نعرف منطقة الرفض بالمنطقة التي تكون فيها :
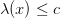 بحيث
بحيث 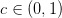
لنفرض مثلا لوكان لدينا عينة مأخوذة من توزيع طبيعي 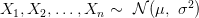 ولتسهيل الأمور لنفرض أننا نعرف قيمة
ولتسهيل الأمور لنفرض أننا نعرف قيمة 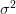 لكن لا نعرف قيمة
لكن لا نعرف قيمة 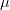 ونريد أن نتأكد من الفرضية:
ونريد أن نتأكد من الفرضية:
 ضد
ضد 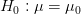
نقوم أولا بتحديد المجالات في كل من الفرضيات. لدينا 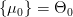 و
و 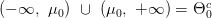 .
.
ثم نحدد دالة الامكان :
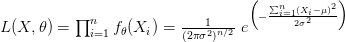
ثم نقوم بحساب قيمة الامكان الأكبر في كلا المجالين و 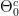 :
:
في المجال بما أنه توجد قيمة واحدة فأكبر قيمة 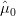 يمكن أتأخذها دالة الإمكان في هذا المجال هي فقط في القيمة
يمكن أتأخذها دالة الإمكان في هذا المجال هي فقط في القيمة 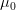

إذن:
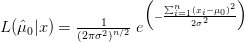
في المجال يمكننا حساب قيمة الإمكان الأكبر بحساب القيمة التي تجعل المشتقة تساوي صفر فنجد أنها تساوي قيمة الوسط الحسابي:

نعوض هذه القيمة في دالة الإمكان فنجد :

يمكننا الآن حساب القيمة الإحصائية 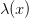 وبعد بضع عمليات الاختزال نتحصل على:
وبعد بضع عمليات الاختزال نتحصل على:
![\lambda(x) = \tfrac{L(\mu_0 | x)}{ L(\bar{x} | x) } = exp \Big [ - \tfrac{(\bar{x}-\mu_0)^2}{2\sigma^2/n} \Big ]](http://www.bioinfo4arabs.com/wp-content/plugins/latex/cache/tex_072ede93d078a5330d02b13966034784.gif)
لدينا العبارة 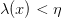 مكافئة للعبارة:
مكافئة للعبارة:
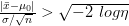
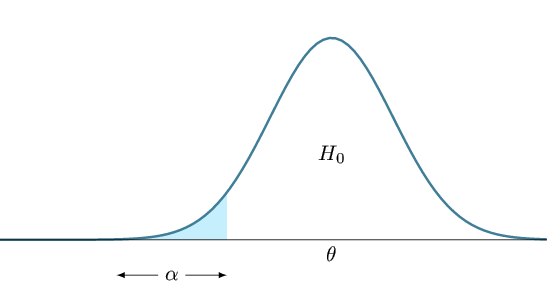
للتبسيط الكتابة نضع 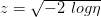 . يمكننا إذن تعريف منطقة الرفض كماهو في المعادلة وكما هو موضح في الشكل.
. يمكننا إذن تعريف منطقة الرفض كماهو في المعادلة وكما هو موضح في الشكل.
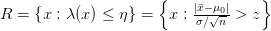
إذا كانت لك خلفية عن اختبار الفرضيات فسترى أن هذا المجال شكله مألوف. في الحقيقة ماهو إلا إختبار زي للعينة الواحدة ثنائي الحد (two sided Z-test for one sample).
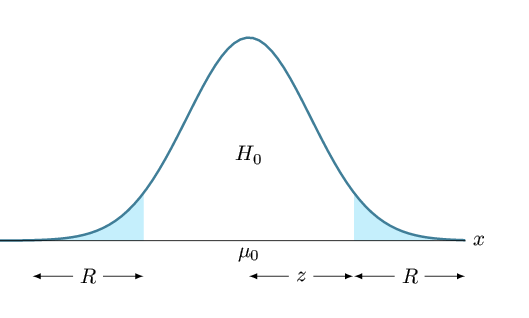
رسم بياني يوضح منطقة الرفض في إختبار زي للعينة الواحدة.
يمكننا إذن بنفس الطريقة تحديد أنواع الإختبارات للحالات الأخرى.
طرق تقييم اختبار الفرضيات:
كما نوهنا فيما سبق أنه بعد تحديد منطقة الرفض يجب تحديد مدى نسبة الخطأ الذي يمكننا ارتكابه عن رفض الفرضية الصفرية أو ما يسمى بالـ p-value. بالإضافة إلى قيم أخرى يمكننا تلخيصها في الجدول التالي:
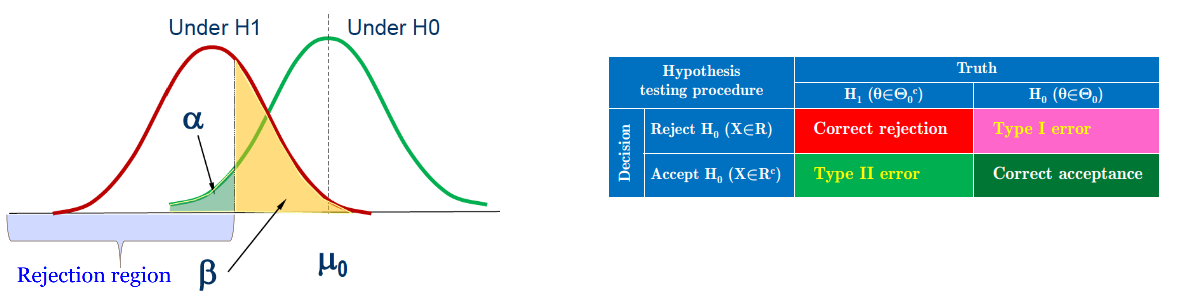
توضيح القيم المستعملة لقيم إختبار الفرضيات
في هذا الجدول يمكننا أن نلاحظ أنه يمكننا القيام بأربعة أنواع من القرارت إثنان منها صحيحة (الأحمر و الأخضر الداكن) و إثنان منها خاطئة (الأخضر الفاتح و البنفسجي).
في الحالات الصحيحة هو عندما تكون لدينا قيم تنتمي إلى الفرضية الصفرية و نصنفها على أنها تنتمي للفرضية الصفرية (المربع الأخضر) أو عندما تكون تنتمي إلى الفرضية البديلة ونصنفها على أنها في الفرضية البديلة (المربع الأحمر).
لكن يمكننا أن نرتكب نوعين من الأخطاء:
- خطأ من النوع الأول (Type I error) : في هذه الحالة (المربع البنفسجي) تكون لدينا بيانات تنتنمي إلى الفرضية الصفرية لكن صنفناها على أنها في الفرضية البديلة وتسمى هذه القيمة بـ أو p-value.
مثلا لو قمنا باختبر تغير التعبير الجيني للجينات بين الخلايا السرطانية و الخلايا العادية ثم صنفنا مجموعة منهم أنها على أن تعبيرها تغير () لكن في الحقيقة تعبيرها لم يتغير (). في هذه الحالة نقوم مثلا بالاختبار بنسبة خطأ 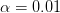 لتقليل الأخطاء.
لتقليل الأخطاء.
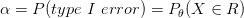
-خطأ من النوع الثاني (type II error) : هذا النوع من الخطأ ( المربع الأخضر الفاتح) يخبرنا بنسبة القيم التي نهتم بها لكن صنفت على أساس أنها غير مهمة. ويرمز عادة إلى هذا الخطأ بالرمز 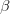 .
.
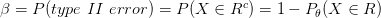
تقاس قوة الإختبار بمدى قدرته على رفضه الفرضية الصفرية لما تكون هذه الأخيرة خاطئة. مثلا نقول أن إختبارنا قوي إذا كانت رفضنا للجينات التي لا تظهر إختلافا جوهريا في تعبيرها بين الخلايا السرطانية و الخلايا العادية.
يمكننا كتابة معادلة قوة الإختبار كالتالي:
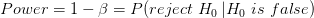
خلاصة:
يمكننا تلخيص عملية القيام بعملية إختبار الفرضيات في الخطوات التالية:
1) كتابة معادلة الإمكان
2) تحديد المجالات و .
3) حساب قيمة الامكان الأكبر في المجال .
4) حساب قيمة الامكان الأكبر في المجال .
5) حساب معادلة القيمة الاحصائية للإختبار.
6) تحديد منطقة الرفض.
7) تقييم الإختبار
في الأخير أتمنى ان يفيد هذا المقال البعض و عذرا على التفصيل في بعض المعادلات الرياضية لكن من وجهة نظري أظن أن معرفة المبدأ وراء هذا النوع من الإختبار هو المهم لانه يسهل علينا فهم نتائج هذه الاختبارات لأننا في العادة لسنا مظطرين للقيام بهذه الحسابات لتوفرها في الكثير من لغات البرمجة. كما يمكن للقارئ أن يستخرج معادلة إختبار الفرضيات في حالة ما كانت لديه بيانات لها توزيع مغاير للتوزيعات المستعملة بكثرة.
ربما في المقالات القادمة سوف نتكلم عن بعض الاختبارات المعروفة مثل إختبار تي واختبار ويلكوكسن (Wilcoxon test) وغيرها. لكن هذا المقال فقط مدخل ولم نتكلم عن الكثير من الأشياء.
رابط المقالة : المعلوماتية الحيوية بالعربية » مدخل إلى الاحتمالات واختبار الفرضيات (الجزء الثاني)