
بسم الله الرحمن الرحيم,
في المقالات السابقة كان تركيزنا على المفاهيم البيولوجية والتعريف ببعض التقنيات لكن بما أننا نتحدث عن المعلوماتية الحيوية فيجب التطرق إلى جانب آخر من هذا المجال وهو تحليل البيانات. تشتمل عمليلة تحليل اللبيانات بصفة عامة على مجموعة من المراحل, هذه المراحل ليست بالظرورة خاصة بمجال المعلوماتية الحيوية لكن بطبيعة الحال في حالة تحليل البيانات البيولوجية يكون هدفنا هو تحليل البيانات بطريقة تكون منسجمة مع المعنى البيولوجي. على حسب علمي أو على حسب ما لاحظت لايوجد تقسيم موحد لعدد مراحل عملية تحليل البيانات لكن يمكن تلخيصها في سبعة مراحل:
1. مرحلة المعالجة التمهيدية (Pre-Processing):
تعتبر هذه المرحلة مرحلة تمهيدية وفي رأيي تعتبر من أهم المراحل. تسمى هذه المرحلة أيضا مرحلة تنظيف البيانات حيث أنها تهدف إلى تحضير البيانات للمعالجة في المراحل القادمة عن طريق جَدْوَلة البيانات ونزع البيانات الناقصة و الأخطاء كما تتضمن أيضا فحص جودة البيانات ونزع البيانات الغير ملائمة أو تصحيحها.
كما هو معلوم, في العادة لما نتحصل على البيانات في شكلها الخام لا تكون دائما مرتبة بالشكل الذي نريد وفي الغالب تكون غير منسقة, مثلا تتحصل على معلومات عن عدة مرضى كل منها في ملف لحاله لكنك تحتاح أن تضعها في جدول واحد أو مثلا في حالة المعلومات البيولوجية تتحصل على بيانات من آلات مختلفة وتكون المعلومات مرتبة بطريقة مختلفة أو تستعمل أسماء مختلفة لبعض الحقول فتحتاج إلى توحيد التسميات وتوحيد بنية الملفات واستخراج قيم الحقول التي تحتاجها.
تتباين نسبة صعوبة هذه المرحلة على حسب نوع البيانات ففي بعض الأحيان تكون هناك برامج جاهزة تسعملها مباشر وهي تقوم بالجزء الأكبر من العمل وفي بعض الأحيان تحتاج الى كتابة بعض السكربيات للقيام بذالك. في العادة البيانات المحفوضة في شكل ملفات ذات بنية متداولة يمكننا فحص جودتها ونزع البيانات ذات النوعية الرديئة باستعمال أدوات جاهزة,مثلا في حالة ملفات Fastq يمكننا استعمال برامج مثل FastQC لدراسة الجودة و Samstools لتنظيف البيانات. لكن في أغلب الأحيان تكون لدينا بيانات مرتبة بطريقة غير متدوالة فيجب علينا كتابة بعض السكريبتات لمعالجتها في العادة تستعمل لغات مثل Perl, python أو الـ R للقيام بذاللك.
2. مرحلة التحليل الوصفي للبيانات (Descriptive analysis):
الهدف الرئيسي من هذه المرحلة هو وصف وتلخيص الخصائص الأساسية للبيانات بحيث تتكون لدينا فكرة عن كيفية توزع البيانات ويمكننا ملاحظة بعض العلاقات بين المتغيرات وبالتالي بناء بعض النظريات عن طريقة تشكل البيانات. يجب التنبيه هنا أن مرحلة التحليل الوصفي لا تسمح لنا بالقيام باستنتاجات أو الجزم بصحة بعض النظريات زيادة عن الوصف الاحصائي للبيانات.
على الرغم من بساطة هذه المرحلة ظاهريا إلا أنها أيضا ذات أهية كبيرة حيث أنها تسمح لنا بالحصول على نظرة مرئية للبيانات ومعرفة سلوكها كمعرفة القيم التي تتركز فيها البيانات وما مدى تشتت البيانات وماهي القيم الشاذة... إلخ.
تستعمل الكثير من الطرق الاحصائية لوصف البيانات والتي يمكن تلخيصها في النقاط التالية:
-) مقاييس النزعة المركزية (Measures of Central tendency: تسمح لنا هذه المقاييس الاحصائية من الحصول على فكرة سريعة على طريقة تمركز البيانات. يمكن تلخيص أكثر المقاييس تداولا في هذا الجدول:
|
المتوسط الحسابي (Arithmetic mean) |
وهو يمثل القيمة التي تتجمع حولها كل القيم. يتم حسابه عن طريق تقسيم مجموع قيم العينات على عدد العينات. يرمز له في العادة بـ: |
|
الوسيط (median) |
وهو القيمة التي يقع 50% من قيم العينات على كل من طرفيها حين ترتب تصاعديا أو نتازليا |
|
المنوال (mode) |
تمثل القيمة الأكثر ترددا بين قيم العينات |
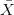
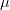
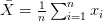
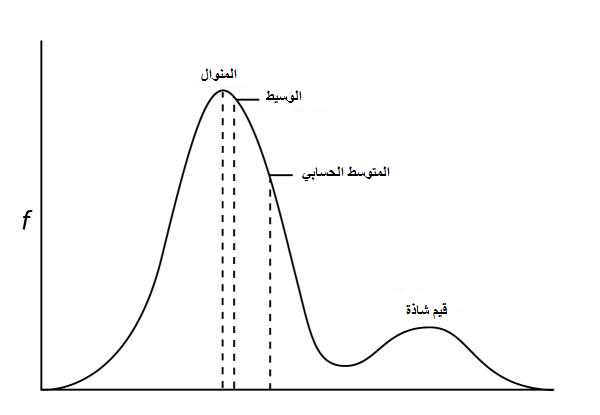
مخطط يوضح بعض مقاييس النزعة المركزية
-) مقاييس التشتت (Variation measure): في العادة مقاييس النزعة المركزية تكون غير كافية من أجل الحصول على نطرة متكاملة عن طريقة توزع البيانات اذ أنها تعطينا بعض المعلومات عن مكان تركز البيانات لكن لاتخبرنا مدى كثافة هذا التمركز. لهذه الأسباب نستعمل معايير التشتت لمعرفة تباعد البيانات فيما بينها. يمكن تلخيص مقاييس التشتت الأكثر الاستعمالا في الجدول التالي:
|
المدى (Range) |
ويمثل الفرق بين أكبر وأصغر قيمة في البيانات |
|
المدى الربيعي (Inter-Quartile range) |
الهدف من هذا المقياس هو محاولة حساب مدى توزع البيانات بدون التأثر بالقيم الشاذة وذالك عن طريق اهمال القيم التي تتكون أقل من 25% من قيم البيانات (الربيع الأول |
|
التباين (Variance) |
يمثل التباين مقدار تباعد أو تشتت البيانات عن المتوسط الحسابي ويساوي متوسط مربع انحراف القيم عن المتوسط الحسابي يمثل في العادة بالرمز |
|
الانحراف المعياري (Standard Deviation) |
يمثل الجذر التربيعي للتباين والهدف منه هو التعبير عن تشتت البيانات باأستعمال وحدة البيانات إذ أن التباين يستعمل وحدة البيانات مربع. يرمز له في العادة بـ |
|
معامل الاختلاف (Coefficient of Variation) |
بستعمل عادة عندما نريد مقارنة التشتت بين عينتين لكن لكل عينة وحدة قياس مختلفة أو اذا كان المتوسط الحسابي مختلف بين العينتين. يتم حساب معامل الاختلاف كالتالي: |
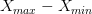
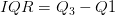
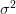
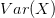
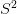
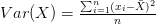
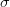
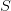
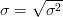
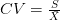
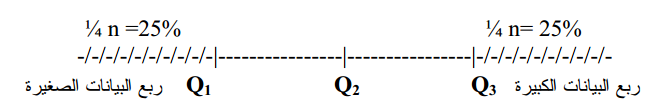
رسم بياني يوضح مبدأ المدى الربيعي (المصدر)
بطبيعة الحال هناك عدة مقاييس أخرى لكن المقاييس المذكورة آنفا تعتبر من الأكثر شيوعا. هناك أيضا مجموعة من المخططات التي تساعدنا على تكوين صورة مرئية عن البيانات مثل المخططات الدائرية (Pie Chart) أو مخطط المستقيمات (Bar Chart). في حالة لما تريد المقارنة بين خصائص عدة مجموعات من البيانات حيث كل مجموعة تحتوي على الكثير من العناصر يمكن استعمال مثلا مخطط الرسم الصندوقي (Box plot) الذي يلخص القيم الخمس (في بعض الأحيان الستة) المحددة للعينة وهي : الربيع الأول 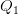 الوسيط
الوسيط 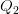 , الربيع الثالث
, الربيع الثالث 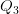 بالاضافة إلى القيمة الصغرى و القيمة الكبرى, لكن في بعض الأحيان نفضل استبدال القيمة الصغرى بقيمة العشر الأول (10%) و قيمة القيمة الكبرى بالعشر التاسع (90%) وتمثيل القيم التي تكون خارج المجال [90%-10%] على شكل نقاط للدلالة على أنها قيم شاذة. في بعض التمثيلات أيضا تضاف علامة + للدلالة على المتوسط الحسابي.
بالاضافة إلى القيمة الصغرى و القيمة الكبرى, لكن في بعض الأحيان نفضل استبدال القيمة الصغرى بقيمة العشر الأول (10%) و قيمة القيمة الكبرى بالعشر التاسع (90%) وتمثيل القيم التي تكون خارج المجال [90%-10%] على شكل نقاط للدلالة على أنها قيم شاذة. في بعض التمثيلات أيضا تضاف علامة + للدلالة على المتوسط الحسابي.

توضيح مبدأ الرسم الصندوقي (مصدر الصورة أ , مصدر الصورة ب)
-) مقاييس شكل التوزع (Distribution Shape) : تعطي هذه المقاييس لمحة عن شكل توزع البيانات مثل مقدار إلتواء (Skewness) وتفرطح (Kurtosis) منحنى توزيع البيانات عن المتوسط الحسابي.

بيان يوضح مبدأ الالتواء
-) مقاييس الاستقلالية (Dependence) : تسمح لنا بحساب نسبة الاستقلالية بين عينتين. بما أننا في مرحلة التحليل الوصفي فإن هذه المرحلة لا تتطلب القيام بعمليات اختبار الفرضيات لكن فقط الحصول على فكرة أولية عن العلاقة بين العينات. في العادة في هذه الخطوة يتم حساب معامل الارتباط (correlation coefficient). يعتبر معامل ارتباط بيرسون (Pearson correlation coefficient) الاكثر شيوعا, في حالة كانت البيانات تخضع لترتيب معين بحيث تعطى رتبة لكل قيمة يتم استعمال معامل ارتباط سبيرمان (Spearman's rank correlation coefficient) .
3. مرحلة التحليل الاستكشافي (Exploratory data analysis):
يمكن تعريف مصطلح التحليل الاستكشافي بأنه منهج (Approach) يتضمن العديد من التقنيات (في العادة مرئية) لتحليل البيانات واكتشاف علاقات غير معروفة وتساعدنا على تشكيل فرضيات جديدة أو حتى مجموعة بيانات جديدة. يساعدنا التحليل الاستكشافي أيضا في تصميم تجارب جديدة.
الهدف من التحليل الاستكشافي هو اعطاء المحلل نوعا من الحدس عن تصرف البيانات, مثلا هل هناك بنية سائدة في البيانات ؟ وما هي التوزيعة الأكثر تفسيرا للبيانات ؟ وماهي المتغيرات المؤثرة و المغيرات الغير مؤثرة في سلوك البيانات ؟ وهل يمكن تمثيل هذه البيانات في بُعْد أصغر من البعد الحالى ؟ وهل يمكن تجميع القيم في مجموعات؟ ... إلخ. للاجابة عن هذه الأسئلة وغيرها نلجئ في هذه المرحلة إلى استعمال المخططات والبيانات بصورة مكثفة.
تم الترويج لهذا المنهج من طرف John Tukey من مختبرات بل والذي حث الاحصائين على اكتشاف البيانات و الذهاب إلى ماوراء البيانات لاكتشاف علاقات وتكوين فرضيات جديدة.
يمكن تصنيف التقنيات المستعملة في هذه المرحلة إلى نوعين: تقنيات مرئية وتقنيات تحليلية أو كمية
-) التقنيات المرئية: و هي التقنيات الأكثر استعمالا حيث أن هذه المرحلة تقوم على مبدأ أن التحليل البصري يُمكننا من رؤية العلاقات بشكل أسرع. من المخططات التي تستعمل في هذه المرحلة هناك الرسوم الصندوقية (Box plot), مخطط الفقاعات (Bubble chart), مخطط التشتت (Scatter plot), المدرجات التكرارية (Histograms).
من المخططات المهمة مخطط Q-Q اختصارا لـ Quantile-Quantile Plot والذي يمكن استعماله لمعاينة مدى مطابقة توزيع قيم العينة مع توزيعة نظرية (مثلا التوزيع الطبيعي) أو مع توزريع قيم عينة اخرى, بحيث يتم وضع قيم الـ Quantile (مثلا الاعشار) للعينية الأولى على المحور العمودي وقيم العينة الثانية في المحور الأفقي, فإذا اِصْطفت هذه القيم على محور 45 درجة للبيان يكننا أن تتشكل لدينا فكرة بأن التوزيعين متشابهين, للتأكد بطريقة أكثر دقة يمكننا استعمال اختبار Kolmogorov–Smirnov.

توضيح للمخطط Q-Q (المصدر)
في مجال المعلوماتية الحيوية يمكن استعمال مخططات أخرى مثل مخطط مانهاتن (Manhattan Plot) التي تستعمل في دراسات الارتباطات الجينومية (GWAS) لدراسة علاقة الطفرات بالأمراض أو التغيرات النمطية بصفة عامة. حيث تُمَثَل الطفرات على المحور الأفقي ويُمَثَل احتمال وجود الارتباط على المحور العموي. تَمثِل القيم الكبرى الطفرات المسؤولة (ملونة بالأخضر في البيان).
![]()
مخطط مانهاتن (مصدر الصورة)
يمكن أيضا استعمالات مخططات أخرى مثل الخرائط الحرارية (Heatmaps) والمخططات الدائرية (Circos plot)
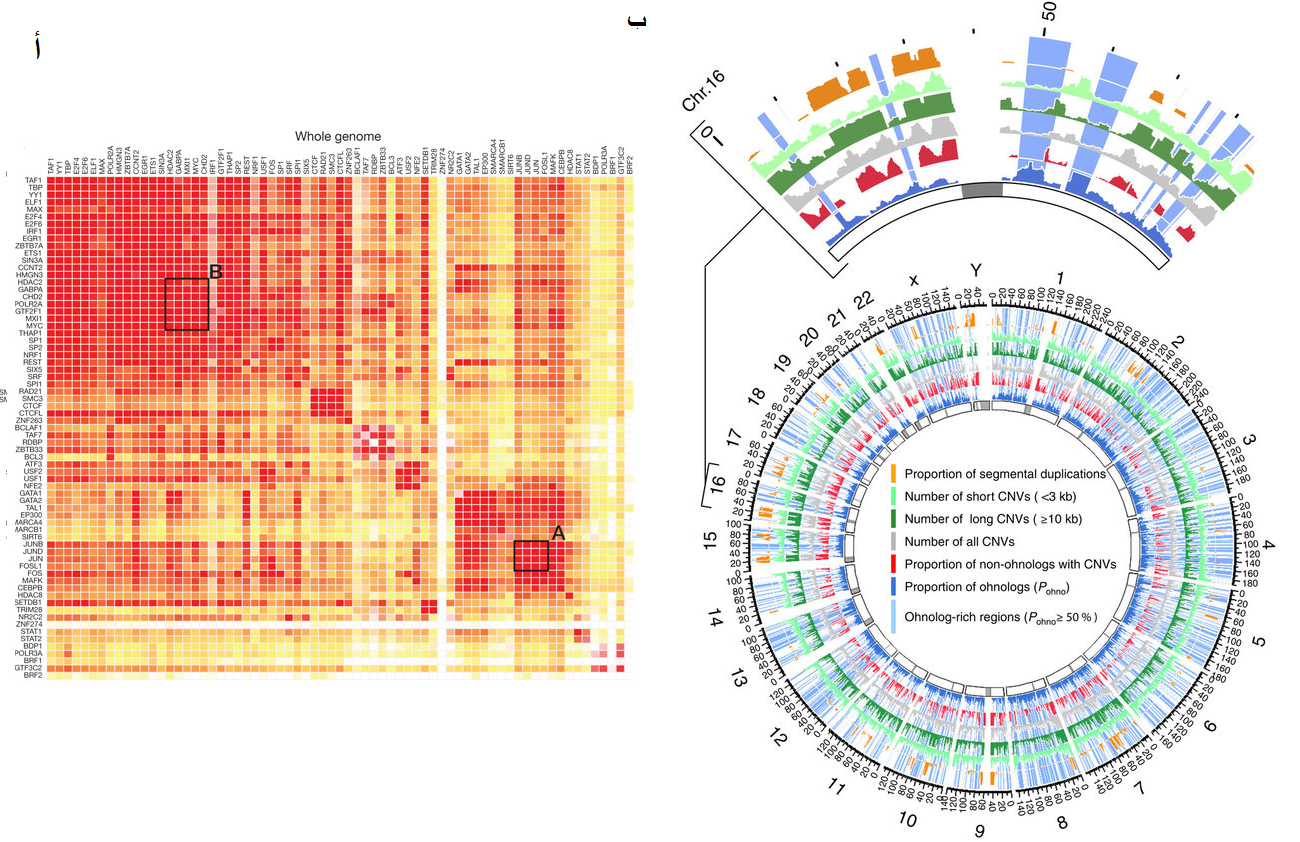
شكل يوضح مخطط الخرائط الحرارية و المخططات الدائرية (مصدر الصورة أ, مصدر الصورة ب)
بالاضافة إلى العديد من المخططات التي لايمكن حصرها في هذا المقال. بالاضافة إلى ذالك يمكن القيام بعمليات تقسيم البيانات إلى مجموعات واظهارها.
-) التقنيات الكمية: تستعمل هذه التقنيات لحساب بعض القياسات و التأكد من أن البيانات تتبع توزعا من التوزيعات باستعمال مثلا اختبار Kolmogorov–Smirnov. يمكن أيضا القيام بعملية تحليل الانحدار (Regression Analysis) لتأكد من وجود علاقة خطية أو غير خطية بين عينتبن.
في حالة تحليل بيانات متتعدة المتغيرات نريد في العادة أن نقلص عدد المتغيرات لأنه في بعض الأحيان توجد متغيرات لاتساهم في الخصائص الاحصائية للبيانات بطريقة كبيرة. من بين التحيليلات التي يمكن القيام بها هو تحليل المركبات الرئيسية (PCA) الذي يساعد على اسقاط البيانات في فضاء ذوا أبعاد أقل. هناك أيضا خوارزميات عديدة مشابهة للـ PCA مثل خوارزمية EDA وغيرها.
من أهم التحليلات أيضا هو البحث عن المجموعات (Clustering) وتصنيف البيانات بطريقة آلية. الهدف من هذا التحليل هو معرفة الأشكال البيانية الخفية للبيانات واستخلاص بعض العلاقات بين العناصر. يوجد العديد من الخوارزميات التي يمكن استعمالها, لعل أسهلها وأكثرها استعمالا خوارزمية الـ k-means و التجميع الهرمي (Hierachical Clustering) وبعضها أكثر تعقيدا مثل الـ HDA وغيرها.

الصورة أ توضح عملية PCA زائد عملية تجميع. الصورة ب توضح عملية التجميع الهرمي (مصدر الصورة بتصرف)
4. مرحلة التحليل الاستدلالي (Inferential Data Analysis):
الهدف الرئيسي من هذه المرحلة هو تعميم النتائج أو الفرضيات واستنتاج خصائص مجتمع احصائي استنادا إلى خصائص العينات. لتوضيح الفكرة, لنفرض مثلا أننا نريد دراسة العلاقة بين التعبير الجيني و ميثيلة الحمض النووي, في الحالة المثالية يجب أن نحلل التعبير الجيني و ميثيلية الحمض النووي لكل البشر على سطح الأرض ونقوم بدراسة هذه العلاقة, لكن هذا مستحيل لعدة أسباب. فالذي نريد فعله هو أن نأخذ بعض العينات, مثلا 100 عينة, ونقوم بتحليلها ثم تعميم هذه النتائج على سكان الكرة الأرضية أو مايسمى بالمجتمع الاحصائي.
يوجد نوعين من التحليل الاستدلالي, الأول هو اختبار الفرضيات (Hypothesis Testing), مثلا نريد معرفة هل المتوسط الحسابي للعينة الأولى يساوي المتوسط الحسابي للعينة الثانية أو هل القيم المتحصل عليها موزعة عشوائيا أم بطريقة غير عشوائية. يمكن استعمال عدة طرقة لاختبار الفرضيات مثل اختبار تي (t-test) في حالة المقارنة بين عينتين أو اختبار ANOVA للمقارنة بين عدة عينات بالاضافة إلى عدة اختبارات أخرى. في العادة نحسب قيمة تسمي بالـ P-value والتي تمثل احتمال صحة الفرضية عشوائيا كلما كانت هذه القيمة صغيرة كلما زادت الدلالة الاحصائية للاختبار. في العادة نعتبر أن الاختبار ذو مدلول احصائي إذا كانت الـ P-value أقل من 0.05 أو 0.01 .
النوع الثاني من التحليل الاستدلالي هو التقدير الاحصائي (statistical estimation). وهو ينقسم أيضا إلى نوعين, النوع الأول هو التقدير النقطي (Point estimation), أبسط مثال على ذللك هو تقدير المتوسط العددي للمجتمع الاحصائي (ليس العينة). في هذا النوع من النوع من التقدير في العادة يكون لدينا نموذج احصائي (معادلة تضم علاقة بين المتغيرات العشوائية) ونحاول نقدير قيمة معاملات (Parameters) النموذج. يمكن بعدها استعمال هذا النموذج للتنبئ بقيم جديدة.
النوع الثاني من التقدير الاحصائي هو تقدير المجالات (Interval estimation) حيث نحاول تقدير مجالات الثقة, مثلا متى أكون واثقا بنسبة 95% من صحة قيمة المعامل الذي تم تقديره.
هناك مدرستان للتحليل الاستدلالي, المدرسة الاولى وهم التكراريون (frequentist) شعارهم هو أن معاملات النموذح الاحصائى ثابتة والبيانات عشوائية (models deterministic, data random) وسلاحهم هو طريقة الإمكان الأكبر (Maximum Likelihood Estimator) أو اختصارا MLE. من الطرف الآخر لدينا البايزيين (Baysians) وشعارهم هو أن معاملات النموذج الاحصائي عشوائية والبيانات ثابتة (مع أخطاء في الحساب طبعا) (models random, data deterministic) لهذا فهم يرون بضرورة اضافة بعض المعلومات المسبقة (prior belifs) للنموذج وسلاحهم نظرية بايز (Bayes Theory) . يتصارع ويتوافق في بعض الاحيان أنصار هذين المدرستين لكن موضوع هذا الصراع ليس موضوعنا :).
في العادة في مجال المعلوماتية الحيوية يميل الباحثون إلى تطورير خوازميات مبنية على مبدأ نظرية بايز لأن استعمال الطرق التكرارية في أغلب الحالات يكون مستحيلا نظرا لحجم البيانات الكبير وكبر فضاء الاحتمالات مما يستلزم وقتا كبيرا. فاستعمال طرق بايز يسمح لنا بالحصول على قيم تقريبية تفي بالغرض.
5. مرحلة التحليل التنبؤي (Predictive Data Analysis):
الهدف من هذه المرحلة هو استعمال نماذج احصائية (التي تم تقدير معاملاتها في المرحلة السابقة) للتنبئ بالنتائج المستقبلية. مثلا التنبئ بمجموعة الجينات التي تلعب دورا في السرطان استنادا إلى تعبيرها الجيني. بطبيعة الحال هناك مقدار من الخطئ أثنا القيام بالعملية ويجب إما تعديل النموذج الاحصائي أو القيام بتجارب للتأكد من صحة النتائج. لكن الهدف اللرئيسي من هذه المرحلة هو اقتراح مجموعة صغير من البيانات ذات دلالة احصائية لدراستها عوض دراسة كل عناصر العينة.
6. مرحلة التحليل السببي (Causal data Analysis):
في الدراسات المتقدمة, نريد مثلا معرفة من من المتغيرات يسب من. تستعملا أيضا مجموعة من الأدوات الاحصائية للقيام بذالك. من بين الأسئلة التي تدرس بكثرة هي ايجاد العلاقة التنظيمية بين الجينات (Gene regulation) أو مثلا في الشبكات الاجتماعية نريد دراسة تاثير الأصدقاء على بعضهم البعض,... إلخ.
7. مرحلة التحليل الميكانيكي (Mechanistic data Analysis):
الهدف من هذه المرحلة هو دراسة آليات حدوث التأثير بين المتغيرات. في العادة تكون التحاليل في هذه المرحلة صعبة وتكون الدراسة في العادة على نموذج صغير من البيانات. تستعمل هذه المرحلة كثيرا في مجال البيولوجية التخليقية (Sythetic Biology) لمحاكات مثلا تأثير التركيز المولي لبروتين من البروتينات على البروتينات الأخرى وتصميم بعض الأنظمة الاصطناعية للتحكم بالخلية. مثلا يمكن تصميم شبكات تفاعل بين بروتينات بحيث تنتج نوعا من البروتينات في وجود محفر من المحفزات. تستعمل البيولوجيا التخليقية في العادة من أجل التصنيع, مثلا الآن نستطيع برمجة البكتيريا لانتاج البلاستيك (Bioplastic) أو بعض الزيوت وهي مستعملة بكثرة في وقتنا الحالي.
وفي الاخير نأكد أنه أثناء القيام بعملية تحليل البيانات لايجب المرور بكل هذه المراحل في العادة يتم القيام بالتحليلات الثلاثة أو الأربعة الأولى. هناك عدة أدوات للقيام بذالك وأكثرها استعمالا في مجال المعلوماتية الحيوية هي لغة الـ R حيث تم تطوير العديد من الحزم التي تقوم بأغلب هذه التحليلات التي يمكن تحميلها من Bioconductor و الـ CRAN. في المقالات القادمة سوف نتطرق إلى بعض الامثلة ان شاء الله.

رابط المقالة : المعلوماتية الحيوية بالعربية » بعض المبادئ الاحصائية في تحليل البيانات







{kind=link}
{kind=link}